
En ce moment j’expérimente pas mal avec les modèles d’IA générative et ça commence à vite coûter cher. J’utilise pas mal le modèle Pay-As-You-Go et les crédits se paient vite une petite fortune.
Mon rêve serait de pouvoir héberger de petits LLM chez moi mais le matériel n’est globalement pas prêt. J’imagine que d’ici quelques années les TPU seront partout. C’est pourquoi en attendant, j’ai décidé d’expérimenter avec mon PC de gaming. Il s’agit d’une tour sous windows et munie d’une carte graphique AMD RX 9070 XT ainsi que d’un processeur AMD Ryzen 7 9700X. Avec cette configuration, on devrait pouvoir faire quelques trucs 👀
Premiers essais #
Pour les drivers, pas de soucis à déclarer, j’ai simplement utilisé les derniers drivers disponibles sous windows fourni par AMD via son logiciel AMD Adrenalin. Dans le doute, j’ai quand même installé le SDK HIP d’AMD pour profiter de la plateforme ROCm. Par la suite ça ne semble pas avoir servi à grand chose mais je me le garde en tête.
J’ai débuté mes essais avec Ollama. Le logiciel est simple et depuis quelques versions, on a même une petite GUI agréable. Cependant, ollama ne semble ne pas supporter ma carte graphique et les modèles ne tourne qu’avec l’accélération CPU. Dans leur article de 2024 ils évoquent un support préliminaire des GPU AMD sous windows et linux mais le nombre de références de cartes supportées reste ridiculement faible…

Jan entre en scène #
Déçu de mes essais non concluants avec Ollama, je suis parti à la recherche d’alternatives. J’ai beaucoup entendu parler de LM Studio. L’application fonctionne bien, mais le fait que le logiciel soit propriétaire m’a vite refroidi.
Je suis donc parti sur Jan, son pendant open source.
À la différence d’Ollama qui utilise son propre backend pour inférer les modèles, Jan se base sur llama.cpp. Par défaut l’application installe la dernière version pour CPU. La petite astuce consiste donc à lui faire installer la version compilée pour supporter l’API Vulkan.
Le projet llama.cpp sortant des versions toutes les quelques heures, j’ai téléchargé la dernière version en date b7356.
Attention à bien télécharger la version Windows x64 (Vulkan)
Puis nous importons le backend en sélectionnant “Install Backend from File”. Pas besoin de décompresser l’archive Jan se charge de tout.
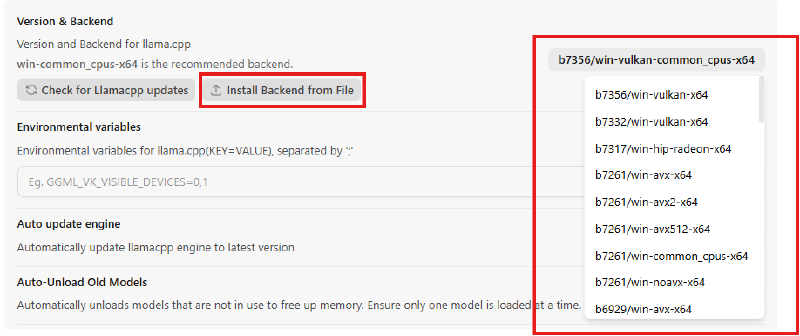
Et enfin, on sélectionne le bon backend sous Vulkan.
En mode serveur #
Faire tourner son modèle sur un poste c’est marrant deux minutes mais nous on aimerait bien pouvoir y accéder à distance. Et peut être même l’ouvrir à des proches.
Pour garantir des communications chiffrées et qui passent les pare-feu sans se prendre la tête, je suis très friand des solutions de VPN mesh. Je suis parti sur mon chouchou netbird. Un des avantages pour mon usage, c’est que j’ai déjà installé le client netbird sur l’ensemble de mes appareils pour pouvoir y accéder à distance. Seule petite modification résiduelle : modifier le filtrage entre mes nœuds. J’ai donc créé une politique pour autoriser certains de mes appareils à accéder à mon instance de Jan sur le port 1337.

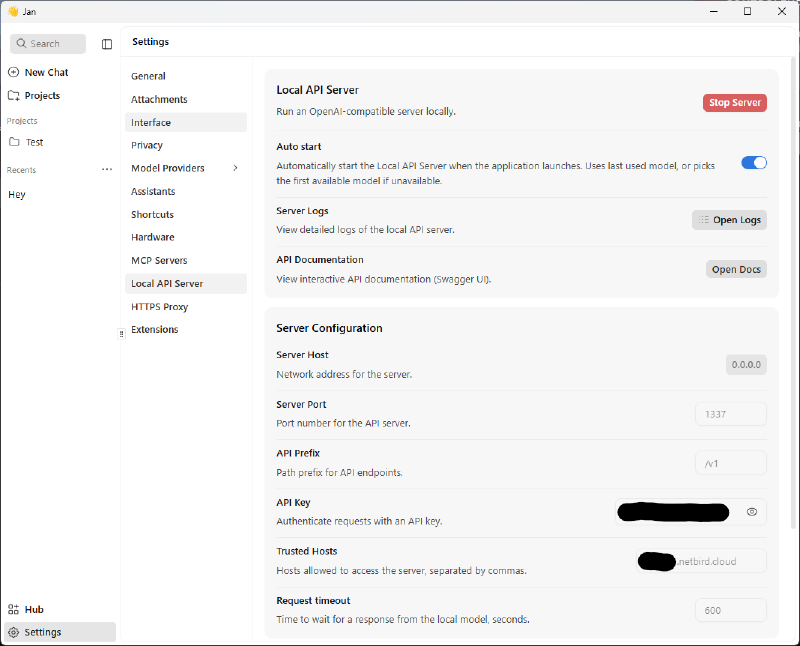
Enfin, il suffit de lancer Jan en mode serveur depuis les paramètres de l’application.
Attention à bien changer l’adresse d’écoute par 0.0.0.0 et de donner un bearer token.
Accéder à distance #
Tout est maintenant en place. Pour tester, j’utilise une autre instance de Jan tournant sur un laptop. Pour cela j’ajoute un provider compatible avec l’API OpenAI et je le fais pointer vers mon serveur.
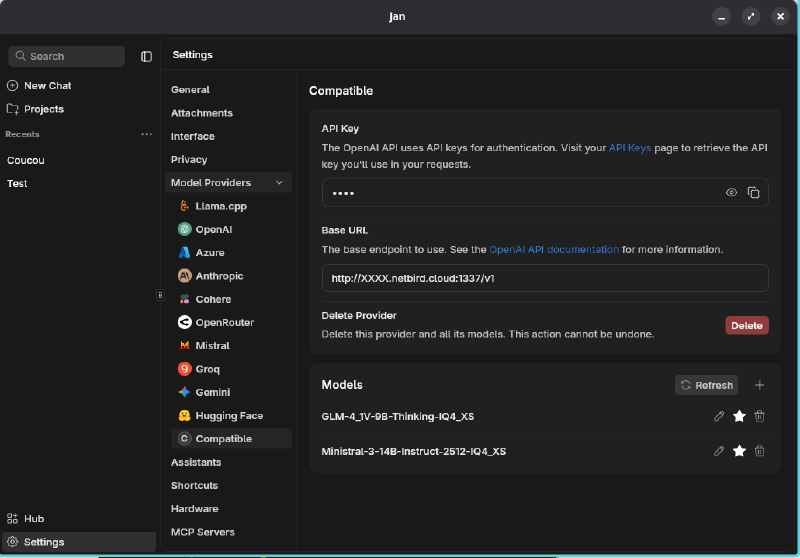
Et tadam, nous avons désormais notre propre serveur qui expose une API OpenAI dans notre réseau 🥳
Avec cette installation j’arrive à environ 50 tokens en moyenne sur le dernier modèle Ministral 3 14B 🪄
